
PostgreSql使用FDW查询慢问题排查
问题回顾
在上周使用FDW实现系统一个功能时, 遇到一个很奇怪的问题, 同样的一条语句, 在FDW表中查询, 比直接在数据库(视图)中查询慢5倍左右, 而且这个时间很稳定, 而且, 同时使用了FDW连接另外一个数据库的另一张视图, 却没有这个问题.
关键词
PosgtesqlFDW, 游标, 索引
正文
系统的数据架构大概如下:

其中两个目标数据库是产品的两个功能, 二者结构大抵类似.
在view_a中大概有 3000w 数据, 使用一个查询 sql, 在f_table_a中耗时约 100s , 而如果直接拿对应的语句去view_a中查询的话, 却只要花费约 20s 左右便可查出. 这样一个结果存在两个问题:
- 如果 FDW 是将查询转发到外部表, 然后返回对应的数据的话, 这个时间差不应该会这么大
- 一个查询语句花了近20s的时间
在类似的f_table_b中查询类似的语句表现的结果是, 不论在 fdw 库中, 还是在目标库中都是花了15-20秒左右的时间, 所以一开始并没有关注第二个问题, 而是主要把时间花在第一个问题上.
PostgreSql FDW 的执行过程
fetch_size
起初, 我一直认为FDW在进行查询的时候, 是把查询语句直接转发到目标数据库, 然后将查询的结果返回客户端. 可是从上面的问题表现来看, 这个道理无论如何解释不通.
因为执行执行比较长, 所以在目标数据库很容易捕捉到执行的语句:
select * from pg_stat_activity
where state != 'idle'
and now() - query_start > interval '60s'
得到耗时的语句如下:
FETCT 100 FROM c1;
而在FDW的文档中也有提到, 可以设置远程执行选项字段中的fetch_size, 默认值为 100.
莫非 ...
好, 将fetch_size设置为: 10000 :
ALTER SERVER server_a OPTIONS ('fetch_size', 10000);
--> nothing change.
游标(cursor)
然后因为查询的语句是FETCH, 于是想到是不是与游标相关. 然后找到了这篇文章(划重点)
事实上在FDW的文档中也有提到, FDW"大体上覆盖了较老的dblink模块的功能", 而dblik对数据的查询就是游标
文章提到, FDW查询数据, 并不是简单的转发查询然后将结果返回给FDW表, 而是先以查询语句创建一个游标, 并查询, 每次获取fetch_size行数据并传回FDW表, 知道没有更多数据结束:

于是照猫画虎, 在目标表上用同样的方式进行查询, 并且这一次一个数据, 排除数据量引起的网络问题的影响
-- 直接查询
-- EXPLAIN (ANALYZE, costs, VERBOSE, buffers, timing)
SELECT COUNT(0)
FROM view_a
WHERE x_date < now();
-- 游标查询(模拟FDW的获取数据过程)
START TRANSACTION ISOLATION LEVEL REPEATABLE READ;
-- EXPLAIN (ANALYZE, costs, VERBOSE, buffers, timing)
DECLARE c1 CURSOR FOR
SELECT COUNT(0)
FROM view_a
WHERE x_date < now();
FETCH 100 FROM c1;
CLOSE c1;
COMMIT TRANSACTION;
结果发现表现一致: 以游标查询的语句, 在FETCH 100 FROM c1;这一行上执行的时间特变慢, 是直接查询语句的接近5倍. 那么这样看来, 大概跟游标有些关系了.
索引
于是打开上面的代码中EXPLAIN (ANALYZE, costs, VERBOSE, buffers, timing)注释, 分别对两个语句进行分析, 发现大地流程相同, 但是在其中一张表(最主要的表, 且数据量最大)却有些不一样:
直接查询:
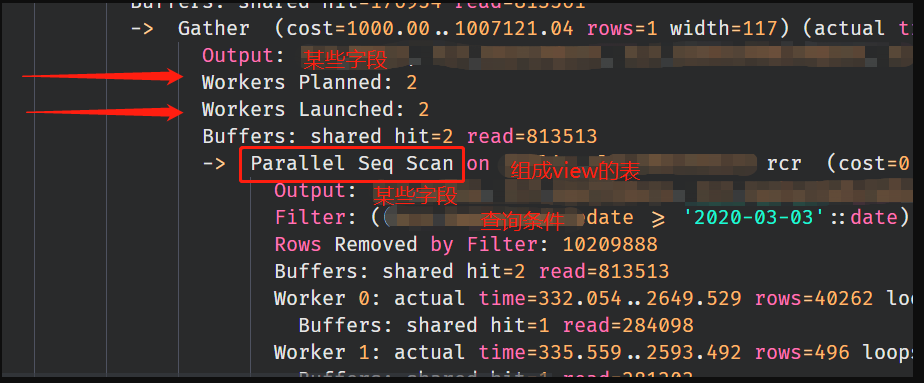
游标查询:
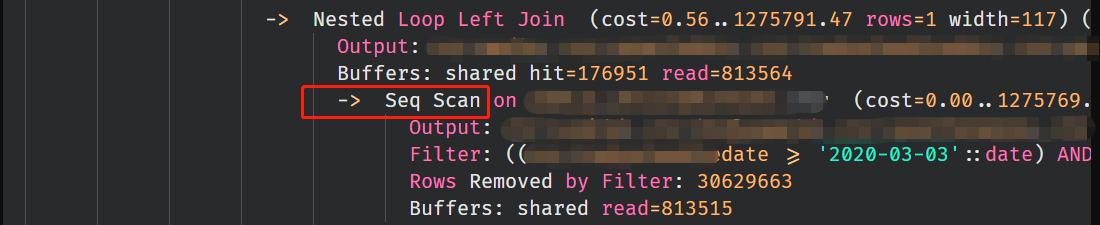
如图中红色方框所示, 对于rcr这张表, 两条语句都用到了全表扫描, 但是直接查询的时候触发了并行扫描, 而在游标查询的语句中却没有触发 导致了通过游标获取数据的时候, 比直接查询满了很多(倍数大概只是巧合).
而为什么会触发全表扫描呢?
select * from pg_indexes where tablename = 'rcr'发现 rcr 表中并没有定义聚集索引.- 查询条件
x_date对应的是rcr.x_date, 并且这个字段没有在任何一条索引中.
根据pg对索引的选择可以知道, 在这种情况向下, 数据库无法选择任何一个已有的索引进行查询, 所以只能进行全表扫描.
注: 索引选择还是通过explain语句分析最靠谱. 附另一篇文章: https://thoughtbot.com/blog/why-postgres-wont-always-use-an-index
因为 rcr 表的数据量较大, 对于这样一张表进行全表扫描是一个很不划算的事情, 于是将视图的定义修改了一下, 选择一个有索引的字段进行查询(或者修改rcr表的索引, 将x_date添加到索引中(这一步没有做))
结果: 重新跑一下查询语句, 结果两者的时间差不多, 并且都在1s内完成.
其他:
-
FDW的基本使用: https://www.jianshu.com/p/1e5b86e8821d (可能后面会写(水)一篇)
-
关于索引, 了解的还不够透彻, 后面也可能会水一篇 (疯狂立flag)
结论:
- FDW 对查询的处理不是简单的转发, 具体来说, 如果外部表也是pg, 则会创建游标查询, 分配次获取数据并回传. 对于其他外部表(比如mysql)则是直接转发请求获取数据.
- 游标查询对于全表扫描无法使用并行扫描.
- 对于所有的数据查询, 要尽量控制查询条件可以利用到表的索引.
